The Simple Explanation
Imagine you have a giant library filled with millions of books, covering all kinds of topics. Now, imagine a super-smart librarian who has read all these books and can quickly find the information you need or create new, unique stories based on what they’ve read.
A large language model like GPT-4o (which is just one of many types) works in a similar way. Here’s a simple breakdown:
- Learning from Texts: First, GPT-4o was trained on a vast amount of text from books, articles, websites, and more. During this training, it learns patterns, grammar, facts, and even some reasoning abilities. It’s like teaching the super-smart librarian by letting them read millions of books.
- Understanding Context: When you ask GPT-4o a question or give it a prompt, it doesn’t just look at the words individually. Instead, it understands the context, meaning it looks at the whole sentence, paragraph, or even the entire conversation to figure out the best response. It’s like asking our librarian to understand not just a word, but the whole story around it.
- Generating Responses: After understanding the context, GPT-4o generates a response. It doesn’t just repeat what it has read; it combines bits of information in a new way to create a meaningful answer. Imagine our librarian not just quoting a book but creating a new summary or story based on everything they’ve read.
- Refining Answers: The model is designed to give more accurate and relevant responses. It does this by predicting the next word in a sentence based on the previous words, refining its answer until it makes sense. Our librarian does this by thinking carefully about each word they choose to make sure their explanation is clear.
To sum it up, GPT-4o is like a super-smart librarian who has read and learned from a vast library of texts. It understands your questions by looking at the whole context, and then it generates new, meaningful responses based on what it has learned. This allows it to assist with a wide range of tasks, from answering questions to writing essays or stories.
The More Detailed Explanation
Understanding exactly how LLMs work is highly complex and requires a deep understanding of mathematics and computer science. Therefore, it is rather more important for you to know what they are doing. This involves a sequence of complex processes, starting from tokenization of training data to generating responses. Here’s a step-by-step explanation:
-
Tokenization:
Tokenization is the first step in preparing data for LLMs. This process involves breaking down raw text into smaller, manageable units known as tokens. These tokens can be words, subwords, or even characters, depending on the granularity needed for the model’s tasks. Tokenization helps in handling the diversity of language by standardizing the input and making it computable for neural networks.
OpenAI has a very nice interface for viewing how their tokenizer works! If you play with this for a few minutes, this concept will be much clearer.
-
Encoding Positional Information:
Once text data is tokenized, the next step is embedding, where each token is converted into a numerical vector that the model can process. Embeddings represent tokens in a way that preserves semantic meaning, allowing words or tokens with similar meanings to have similar representation in vector space (a mathematical model of multi-dimensional space).
Embeddings can be created using various techniques. However, more advanced LLMs often utilize neural network-based methods to learn these embeddings directly from data. This includes methods like Word2Vec and ELMo, where embeddings are trained to predict linguistic contexts of words, effectively capturing deeper semantic and syntactic meanings of the language.
Basically, you can imagine embeddings as being meaningful points in some very high dimensional space which only a computer can access because the human brain can only really think in 3 dimensions.
-
Attention Mechanism:
The core of a transformer model, which most LLMs are based on, is the attention mechanism. This allows the model to focus on different parts of the input sequence as needed. The attention mechanism computes scores that determine how much focus to place on other parts of the input for each token in the sequence. This helps in understanding context and relationships between words. Without the attention mechanism, nothing would work.

(image source) -
Training: Pre-training and Fine-tuning:
LLMs undergo two main phases of training. In the pre-training phase, the model learns general language patterns from a large corpus of text data (like books, websites, etc.) using unsupervised learning. This stage helps the model understand basic language structure and word associations.Fine-tuning occurs after pre-training and is more specialized. Here, the model is trained on a narrower set of data tailored to specific tasks like translation, sentiment analysis, or question answering. This phase often involves supervised learning, sometimes enhanced by techniques like reinforcement learning from human feedback to refine the model’s accuracy on particular tasks.
-
RLHF: Reinforcement Learning from Human Feedback
Data Collection:
RLHF starts with an initial model trained using supervised learning, in which it learns from a dataset of human-written text and is monitored by engineers. However, this initial training might not perfectly align the model’s responses with human preferences in more nuanced scenarios.
Human Feedback:
To refine the model, human reviewers are introduced into the loop. These reviewers interact with the model, providing responses to prompts or tasks. They then rate the model’s outputs or suggest better alternatives. This feedback is crucial as it represents human judgments on what constitutes a good or correct response.
Training with Feedback:
The feedback collected from human reviewers is used to train the model further. This is done through a method known as Proximal Policy Optimization (PPO), a reinforcement learning technique. The model learns to predict not just based on the statistical patterns of language, but also the preferences and corrections suggested by humans. This helps the model to align more closely with human values and preferences.
Iterative Refinement:
This process is iterative, meaning the model can undergo several rounds of feedback and re-training. Each cycle aims to progressively refine the model’s outputs, making them increasingly aligned with human expectations and ethical standards.
Deployment:
Once the model achieves satisfactory performance, as judged by human reviewers, it can be deployed. Even post-deployment, continuous monitoring and occasional re-training with new human feedback might be necessary to maintain the model’s performance and relevance.
-
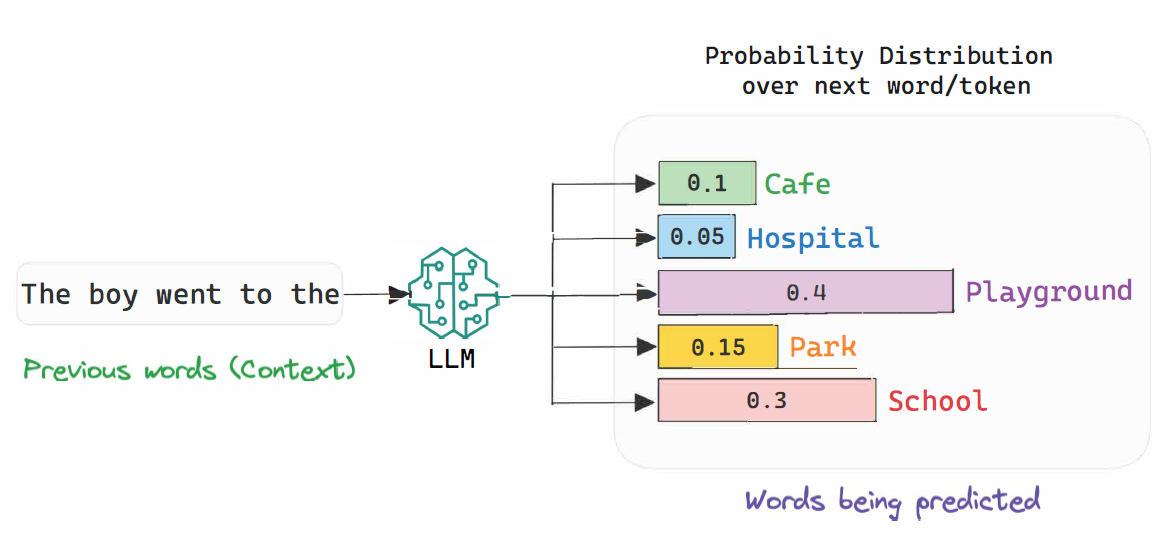
Generation of Tokens:
When generating text, an LLM predicts the next token in a sequence based on the input it receives (for example, the entire conversation history or your question). This involves calculating probabilities for each possible next token and selecting the token with the highest probability. This process repeats for each new word until the model completes its response or reaches a maximum length limit.This is why LLMs use a lot of energy — they make millions of calculations with each next-token prediction, even though they will only choose one word/token with each cycle.
(image source)